Robots.txt Là Gì Và Khi Nào Doanh Nghiệp Nên Quan Tâm Đến File Này?
Insights
GTG CRM Team · GTG CRM
22 Tháng 4 2026
Mục lục bài viết
Robots.txt Là Gì Và Khi Nào Doanh Nghiệp Nên Quan Tâm Đến File Này?
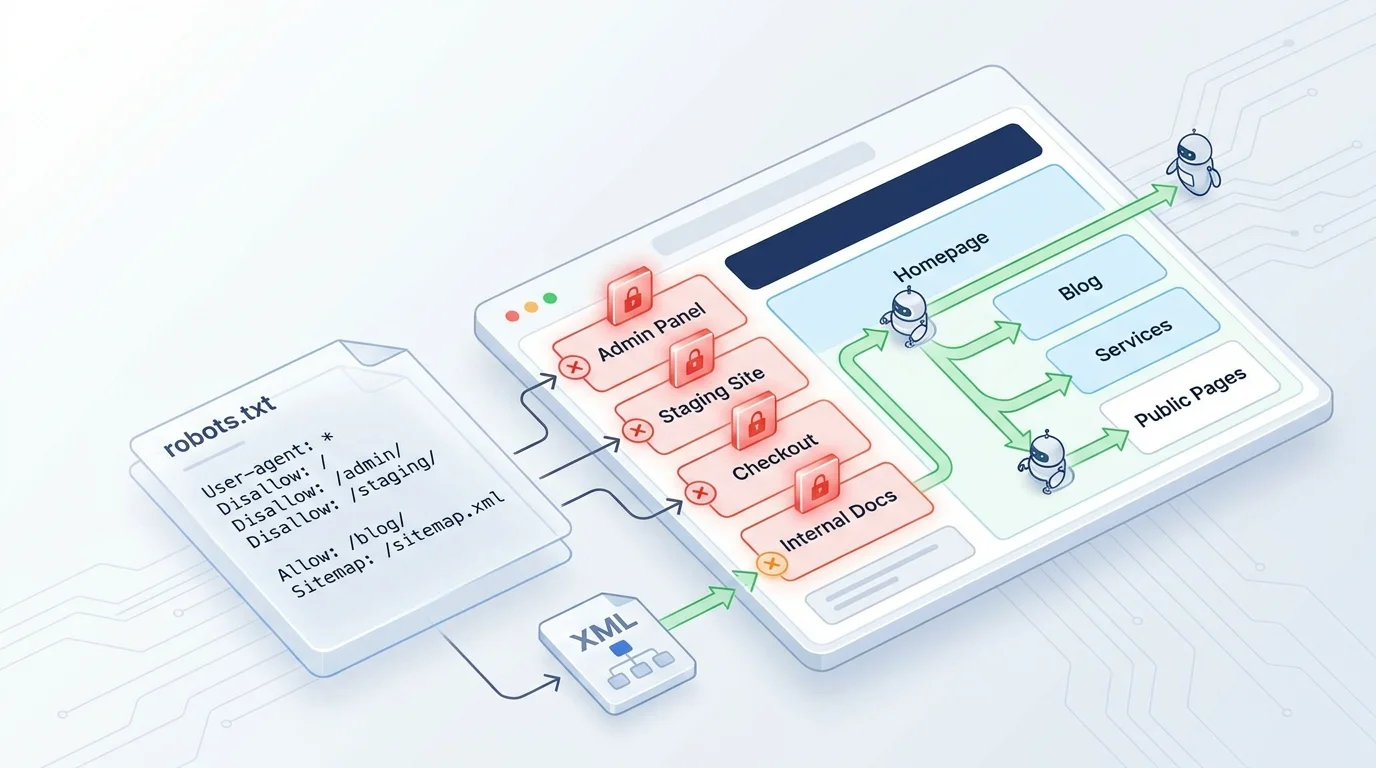
Bạn đã có sitemap, đã gửi cho Google, website cũng bắt đầu được index. Nhưng một ngày, bạn phát hiện trang quản trị (admin), trang thanh toán nội bộ, hoặc trang staging của website cũng xuất hiện trên Google. Khách hàng gõ tên công ty - thấy luôn cả trang test chưa hoàn thiện.
Hoặc ngược lại: bạn đăng bài blog mới, chờ hai tuần vẫn không thấy trên Google. Hỏi đơn vị kỹ thuật, họ nói: "File robots.txt đang chặn Google crawl toàn bộ website."
Cả hai tình huống đều liên quan đến một file nhỏ mà ít người quản lý web để ý: robots.txt.
Bài viết này sẽ giải thích robots.txt là gì, nó hoạt động ra sao, khi nào bạn cần chỉnh sửa nó, và những lỗi phổ biến mà doanh nghiệp cần tránh - tất cả bằng ngôn ngữ đơn giản, kèm ví dụ thực tế.
Robots.txt là gì? Giải thích cho người quản lý web
Nếu sitemap là tấm sơ đồ toà nhà - chỉ cho Google biết có những phòng nào, thì robots.txt là tấm biển "Khu vực hạn chế" - nói cho Google biết phòng nào không được vào.
Nói cách kỹ thuật: robots.txt là một file văn bản nhỏ, nằm ở thư mục gốc của website (ví dụ: https://example.com/robots.txt). File này chứa các quy tắc (rules) nói cho bot của công cụ tìm kiếm - như Googlebot - biết:
- Những trang nào được phép crawl (quét)
- Những trang nào không được phép crawl
- Sitemap nằm ở đâu
Bạn có thể xem robots.txt của bất kỳ website nào bằng cách gõ: ten-mien.com/robots.txt trên trình duyệt.
💡 Quan trọng: robots.txt chỉ là lời yêu cầu lịch sự, không phải lệnh cấm tuyệt đối. Các bot uy tín như Googlebot sẽ tuân thủ, nhưng bot xấu (spam, scraper) có thể bỏ qua. Nếu bạn cần bảo mật thực sự, hãy dùng mật khẩu hoặc tường lửa - đừng dựa vào robots.txt.
File robots.txt trông như thế nào?
Bạn không cần tự viết file này từ đầu. Nhưng để hiểu khi nhìn vào, đây là một file robots.txt đơn giản:
User-agent: *
Disallow: /admin/
Disallow: /thanh-toan/
Disallow: /staging/
Allow: /
Sitemap: https://example.com/sitemap.xml
Giải thích từng dòng:
| Dòng | Ý nghĩa |
|---|---|
User-agent: * | Áp dụng cho tất cả bot (Google, Bing, v.v.) |
Disallow: /admin/ | Không cho bot vào thư mục /admin/ |
Disallow: /thanh-toan/ | Không cho bot vào trang thanh toán |
Disallow: /staging/ | Không cho bot vào phiên bản staging |
Allow: / | Cho phép bot crawl toàn bộ phần còn lại |
Sitemap: https://... | Chỉ cho bot biết sitemap nằm ở đâu |
Dưới đây là một ví dụ phức tạp hơn - phù hợp với website doanh nghiệp có blog, trang dịch vụ, và khu vực quản trị:
# Cho phép tất cả bot crawl nội dung công khai
User-agent: *
Disallow: /admin/
Disallow: /wp-admin/
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /search?
Disallow: /*?ref=
Disallow: /*?utm_
# Cho phép Googlebot crawl CSS và JS (cần thiết để render trang)
User-agent: Googlebot
Allow: /wp-content/uploads/
Allow: /wp-includes/
Sitemap: https://example.com/sitemap.xml
📝 Note cho dev: Ký tự
trong path là wildcard —/?utm_có nghĩa là chặn mọi URL chứa tham số?utm_. Ký tự$ở cuối path dùng để khớp chính xác cuối URL. Ví dụ:Disallow: /*.pdf$sẽ chặn tất cả file PDF.
---
Robots.txt hoạt động như thế nào trong quy trình SEO?
Để hiểu vị trí của robots.txt, hãy nhìn lại quy trình Google đưa trang web vào kết quả tìm kiếm:
Crawl → Index → Rank
(Quét) (Lưu) (Xếp hạng)
Robots.txt hoạt động ở bước đầu tiên - Crawl.
Trước khi Googlebot bắt đầu quét bất kỳ trang nào trên website của bạn, nó sẽ kiểm tra robots.txt trước. Nếu một URL bị liệt kê trong Disallow, Googlebot sẽ bỏ qua trang đó - không quét, không đọc nội dung.
Googlebot muốn crawl https://example.com/admin/settings
→ Kiểm tra robots.txt
→ Thấy Disallow: /admin/
→ Bỏ qua, không crawl
Googlebot muốn crawl https://example.com/dich-vu/
→ Kiểm tra robots.txt
→ Không bị chặn
→ Crawl bình thường → Index → Có thể lên kết quả tìm kiếm
Robots.txt và sitemap: bộ đôi bổ trợ nhau
| File | Vai trò |
|---|---|
| Sitemap | "Đây là danh sách trang tôi muốn Google biết" |
| Robots.txt | "Đây là những trang tôi không muốn Google quét" |
Hai file này không mâu thuẫn - chúng làm việc cùng nhau. Sitemap chỉ đường, robots.txt đặt rào chắn. Kết hợp đúng cách, bạn kiểm soát được Google thấy gì và bỏ qua gì trên website.
Robots.txt dùng để làm gì? 4 trường hợp phổ biến
1. Ẩn trang quản trị và nội bộ khỏi Google
Trang admin, trang CMS backend, trang staging, trang test - tất cả không nên xuất hiện trên Google. Robots.txt giúp bạn nói với Google: "Đừng vào đây."
Disallow: /admin/
Disallow: /wp-admin/
Disallow: /staging/
2. Tránh lãng phí "crawl budget"
Google không crawl vô hạn. Mỗi website có một "ngân sách crawl" (crawl budget) - số trang mà Googlebot sẽ quét trong mỗi lần ghé thăm. Nếu website có nhiều trang không quan trọng (trang tìm kiếm nội bộ, trang filter, trang phân trang), Googlebot có thể bận quét những trang này thay vì trang dịch vụ hay bài blog quan trọng.
Disallow: /search?
Disallow: /tag/
Disallow: /page/
💡 Crawl budget chủ yếu quan trọng với website lớn (hàng nghìn trang). Website doanh nghiệp nhỏ thường không cần quá lo, nhưng giữ robots.txt gọn gàng vẫn là thói quen tốt.
3. Chặn nội dung trùng lặp
Nếu website có nhiều URL dẫn đến cùng một nội dung (ví dụ: URL có tham số tracking ?utm_source=facebook, hoặc phiên bản in ?print=true), bạn có thể chặn các URL trùng lặp này:
Disallow: /*?utm_
Disallow: /*?ref=
Disallow: /*?print=
4. Chỉ đường đến sitemap
Robots.txt là nơi đầu tiên Googlebot kiểm tra khi đến website. Đặt đường dẫn sitemap ở đây giúp Google tìm thấy sitemap nhanh hơn - kể cả khi bạn chưa gửi qua Search Console.
Sitemap: https://example.com/sitemap.xml
Khi nào doanh nghiệp cần quan tâm đến robots.txt?
Không phải lúc nào bạn cũng cần chỉnh robots.txt. Nhưng có những thời điểm mà việc kiểm tra file này là bắt buộc:
Khi website mới được triển khai (go-live)
Đây là thời điểm quan trọng nhất. Rất nhiều website bị chặn crawl hoàn toàn vì đơn vị phát triển quên gỡ dòng Disallow: / - dòng mà họ đặt trong quá trình staging để Google không index phiên bản chưa hoàn thiện.
Kiểm tra khi go-live:
| Hạng mục | Cách kiểm tra |
|---|---|
| File robots.txt tồn tại | Mở https://ten-mien.com/robots.txt trên trình duyệt |
| Không chặn toàn bộ website | Đảm bảo KHÔNG có dòng Disallow: / |
| Có khai báo sitemap | Đảm bảo CÓ dòng Sitemap: https://ten-mien.com/sitemap.xml |
| Trang quan trọng không bị chặn | Kiểm tra trang dịch vụ, blog, liên hệ không nằm trong Disallow |
✅ Khi website không được Google index sau nhiều tuần
Nếu bạn đã có sitemap, đã gửi qua Search Console, nhưng Google vẫn không index - robots.txt là nghi phạm đầu tiên cần kiểm tra.
Khi thêm khu vực cần ẩn (trang thành viên, trang nội bộ)
Nếu website bổ sung trang quản lý tài khoản, khu vực member, hoặc trang nội bộ - hãy cập nhật robots.txt để chặn những khu vực này.
Khi đổi nền tảng website hoặc redesign
Mỗi nền tảng (WordPress, Webflow, custom code) tạo cấu trúc URL khác nhau. Khi migrate, robots.txt cũ có thể chặn nhầm trang mới hoặc bỏ sót trang cần chặn.
Khi Search Console báo lỗi "Blocked by robots.txt"
Google Search Console có báo cáo Indexing cho biết trang nào bị chặn bởi robots.txt. Nếu thấy trang quan trọng bị chặn - đó là lúc cần chỉnh file ngay.
5 lỗi robots.txt phổ biến và cách khắc phục
Lỗi 1: Chặn toàn bộ website - lỗi nghiêm trọng nhất
Biểu hiện: Không trang nào được Google index. Search Console báo hàng loạt trang "Blocked by robots.txt".
Nguyên nhân: File robots.txt chứa:
User-agent:
Disallow: /
Hai dòng này có nghĩa: "Cấm tất cả bot vào bất kỳ trang nào." Thường xảy ra khi dev đặt rule này lúc làm staging và quên gỡ khi go-live.
Cách khắc phục: Sửa thành:
User-agent: *
Disallow:
Sitemap: https://ten-mien.com/sitemap.xml
Disallow: (không có gì sau dấu hai chấm) = cho phép crawl tất cả.
⚠️ Đây là lỗi số 1 mà chúng tôi thấy ở website doanh nghiệp mới. Sau khi sửa, Google có thể mất vài ngày đến vài tuần để crawl lại. Gửi lại sitemap qua Search Console để đẩy nhanh quá trình.
---
Lỗi 2: Chặn CSS và JavaScript
Biểu hiện: Website hiển thị bình thường trên trình duyệt, nhưng khi dùng công cụ "URL Inspection" trong Search Console, Google thấy trang bị vỡ layout hoặc trống nội dung.
Nguyên nhân: Robots.txt chặn thư mục chứa CSS và JS:
Disallow: /wp-content/
Disallow: /wp-includes/
Google cần đọc CSS và JS để hiểu trang trông như thế nào (gọi là "rendering"). Nếu bị chặn, Google không render được trang → không hiểu nội dung → ảnh hưởng đến ranking.
Cách khắc phục:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Allow: /wp-content/
Allow: /wp-includes/
📝 Note cho dev: Kể từ 2014, Google khuyến nghị rõ ràng: không chặn CSS, JS, và hình ảnh trong robots.txt. Googlebot cần các resource này để render trang đúng cách. Dùng URL Inspection tool trong Search Console để kiểm tra Google render trang của bạn ra sao.
Lỗi 3: Chặn nhầm trang quan trọng
Biểu hiện: Trang dịch vụ, trang sản phẩm, hoặc bài blog không xuất hiện trên Google - dù sitemap có liệt kê.
Nguyên nhân: Rule trong robots.txt quá rộng. Ví dụ:
Disallow: /dich-vu
Dòng này chặn không chỉ /dich-vu/ mà còn /dich-vu-thiet-ke-web/, /dich-vu-seo/, và bất kỳ URL nào bắt đầu bằng /dich-vu.
Cách khắc phục: Thêm dấu / cuối path để chặn chính xác thư mục:
Disallow: /dich-vu-noi-bo/
Hoặc dùng Allow để bảo vệ trang cần thiết:
Disallow: /dich-vu-noi-bo/
Allow: /dich-vu/
Allow: /dich-vu-thiet-ke-web/
📝 Note cho dev: Thứ tự
AllowvàDisallowcó ảnh hưởng. Googlebot sử dụng rule cụ thể nhất (most specific path). Nếu cùng độ dài,Allowđược ưu tiên hơnDisallow. Luôn test bằng Robots Testing Tool trong Search Console trước khi deploy.
Lỗi 4: Không có file robots.txt
Biểu hiện: Gõ ten-mien.com/robots.txt → trả về lỗi 404.
Nguyên nhân: Website làm thủ công mà dev không tạo file này. Hoặc file bị xoá nhầm khi deploy.
Ảnh hưởng: Không nghiêm trọng bằng lỗi 1 - nếu không có robots.txt, Google mặc định crawl tất cả. Nhưng điều này có nghĩa:
- Google sẽ crawl cả trang admin, trang test, trang nội bộ
- Bạn không có cách chỉ đường đến sitemap qua robots.txt
- Thiếu kiểm soát cơ bản
Cách khắc phục: Tạo file robots.txt tại thư mục gốc. Nội dung tối thiểu:
User-agent: *
Disallow: /admin/
Disallow: /search?
Sitemap: https://ten-mien.com/sitemap.xml
---
Lỗi 5: Dùng robots.txt để ẩn trang khỏi Google (hiểu sai mục đích)
Biểu hiện: Bạn chặn một trang bằng Disallow, nhưng trang đó vẫn xuất hiện trên Google - dù không có snippet nội dung.
Nguyên nhân: Robots.txt chặn crawl, không chặn index. Nếu trang đã được index trước đó, hoặc có backlink từ website khác trỏ đến, Google có thể giữ URL trong kết quả tìm kiếm - chỉ là không hiển thị nội dung.
Cách khắc phục đúng:
| Mục tiêu | Dùng gì |
|---|---|
| Không muốn Google crawl (quét) | Disallow trong robots.txt |
| Không muốn Google index (hiển thị) | Thẻ |
| Không muốn cả hai | Dùng noindex trong HTML (và không chặn trong robots.txt) |
⚠️ Đây là điểm hay bị hiểu sai nhất: Nếu bạn vừa chặn crawl (robots.txt) vừa đặt
noindex(HTML), Google sẽ không thấy thẻ noindex vì không được crawl trang đó — và trang có thể vẫn bị index. Giải pháp: dùngnoindextrong HTML và bỏ ruleDisallowcho trang đó trong robots.txt.
Robots.txt mẫu cho website doanh nghiệp
Dưới đây là file robots.txt mẫu phù hợp với đa số website doanh nghiệp SMB:
# =============================================
# Robots.txt cho website doanh nghiệp
# Cập nhật: 2026-04-20
# =============================================
# Áp dụng cho tất cả bot
User-agent: *
# Chặn khu vực quản trị và nội bộ
Disallow: /admin/
Disallow: /wp-admin/
Disallow: /dashboard/
Disallow: /staging/
# Chặn trang tìm kiếm nội bộ (tránh lãng phí crawl budget)
Disallow: /search?
Disallow: /*?s=
# Chặn URL có tham số tracking (tránh nội dung trùng lặp)
Disallow: /*?utm_
Disallow: /*?ref=
Disallow: /*?fbclid=
# Chặn trang giỏ hàng / thanh toán (nếu có)
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
# Cho phép CSS, JS, hình ảnh (Google cần để render trang)
Allow: /wp-content/uploads/
Allow: /wp-content/themes/
Allow: /wp-includes/
# Chỉ đường đến sitemap
Sitemap: https://ten-mien.com/sitemap.xml
📝 Note cho dev: File robots.txt phải nằm ở root domain —
https://example.com/robots.txt. Không phải/blog/robots.txthay subdirectory khác. Mỗi subdomain cần robots.txt riêng (ví dụ:blog.example.com/robots.txttách biệt vớiexample.com/robots.txt).
Cách kiểm tra robots.txt của website bạn
Cách 1: Kiểm tra trực tiếp trên trình duyệt
Gõ https://ten-mien-cua-ban.com/robots.txt vào thanh địa chỉ. Bạn sẽ thấy nội dung file dạng text. Nếu thấy lỗi 404 — website chưa có robots.txt.
Cách 2: Dùng Google Search Console
- Đăng nhập Google Search Console
- Vào mục Settings → Crawling → robots.txt
- Xem file robots.txt mà Google đang đọc
- Kiểm tra xem URL cụ thể có bị chặn không
Cách 3: Kiểm tra trong báo cáo Indexing
Trong Search Console → Pages (hoặc Indexing) → Tìm mục "Blocked by robots.txt". Nếu có trang quan trọng trong danh sách này, bạn cần sửa robots.txt ngay.
💡 Nên kiểm tra robots.txt ít nhất mỗi quý hoặc mỗi khi website có thay đổi lớn (thêm trang, đổi cấu trúc, migrate nền tảng).
Bảng tổng hợp: Robots.txt nên chặn gì và không nên chặn gì
| ✅ NÊN chặn | ❌ KHÔNG NÊN chặn |
|---|---|
Trang quản trị (/admin/, /wp-admin/) | Trang chủ, trang dịch vụ, trang liên hệ |
| Trang staging / test | Bài blog, bài viết |
Trang tìm kiếm nội bộ (/search?) | File CSS và JavaScript |
URL có tham số tracking (?utm_, ?fbclid=) | Hình ảnh (Google Images cũng mang traffic) |
| Trang giỏ hàng, thanh toán, tài khoản cá nhân | Sitemap |
| Trang nội dung trùng lặp (filter, sort, phân trang) | Trang FAQ, case study |
---
Câu hỏi thường gặp về robots.txt
Robots.txt và sitemap khác nhau thế nào?
Sitemap nói: "Đây là trang tôi muốn Google biết." Robots.txt nói: "Đây là trang tôi không muốn Google quét." Hai file bổ trợ nhau — sitemap chỉ đường vào, robots.txt đặt rào chắn.
Nếu không có robots.txt, Google có crawl được website không?
Có. Không có robots.txt, Google mặc định crawl tất cả mọi trang — kể cả trang bạn không muốn. Đó là lý do nên có file này.
Tôi dùng WordPress, robots.txt nằm ở đâu?
WordPress tự tạo robots.txt ảo (virtual). Nếu bạn dùng plugin SEO như Yoast hoặc Rank Math, bạn có thể chỉnh robots.txt trực tiếp trong plugin mà không cần truy cập server.
Robots.txt có ảnh hưởng đến tốc độ website không?
Không. File này chỉ nặng vài KB. Nó không ảnh hưởng đến tốc độ tải trang.
Tôi chặn trang bằng robots.txt rồi, sao trang vẫn lên Google?
Vì robots.txt chỉ chặn crawl, không chặn index. Nếu muốn trang hoàn toàn biến mất khỏi Google, dùng thẻ trong HTML - và không chặn trang đó trong robots.txt (để Google đọc được thẻ noindex).
Sửa robots.txt xong, bao lâu thì Google cập nhật?
Google thường kiểm tra lại robots.txt trong vòng 24-48 giờ. Bạn có thể vào Search Console → Settings → Crawling để yêu cầu Google kiểm tra lại sớm hơn.
Kết luận
Robots.txt là một file nhỏ - thường chỉ vài dòng - nhưng ảnh hưởng trực tiếp đến việc Google có thấy website của bạn hay không.
Những điều cần nhớ:
- Robots.txt là tấm biển "Khu vực hạn chế": nói cho Google biết trang nào không được quét
- Kiểm tra ngay khi website go-live: lỗi chặn toàn bộ website là lỗi phổ biến và nghiêm trọng nhất
- Không dùng robots.txt để ẩn trang khỏi Google: nó chặn crawl, không chặn index
- Luôn cho phép CSS và JS: Google cần render trang để hiểu nội dung
- Kết hợp với sitemap và Search Console: để kiểm soát hoàn toàn việc Google crawl và index website
Kiểm tra nền tảng website của bạn
Robots.txt chỉ là một trong nhiều yếu tố kỹ thuật ảnh hưởng đến SEO. Nếu bạn đang tự hỏi: "Website của mình có đang thiết lập đúng không?" - câu trả lời nằm ở nền tảng bạn đang dùng.
GTG CRM giúp bạn có website với robots.txt chuẩn, sitemap tự động, và cấu trúc kỹ thuật sẵn sàng cho Google - bạn không cần lo chỉnh từng file, từng dòng code.
Biến những gì vừa đọc thành kết quả thực tế — áp dụng ngay với GTG CRM, miễn phí.
Áp dụng ngayCó Thể Bạn Quan Tâm

Từ Thất Bại của Toys “R” Us đến Con Đường Chuyển Mình Của Doanh Nghiệp Truyền Thống Trong Kỷ Nguyên Số

MM3.vn - Tự Động Hóa Toàn Bộ Quy Trình Nội Dung

Bật Mí Cách Tối Ưu Quá Trình Kinh Doanh Online Cho Chủ Shop Đồ Gia Dụng

7 case study tối ưu Landing Page thành công nhất

Case Study: Airbnb tăng chuyển đổi 30% nhờ Landing Page tối ưu trải nghiệm

Coolmate - Startup Việt bứt phá doanh thu nhờ CRM và Automation

Là Vè Gourmet, Mầm Spa, Gori Vietnam x3 doanh thu nhờ Landing Page

Case Study: Chị Lan Anh - Từ Bối Rối Quản Lý Đa Kênh Đến Bán Hàng Hiệu Quả Với GTG CRM

Tối ưu hóa mạng xã hội với AI: Bí quyết tăng hiệu suất nội dung cùng Buffer và Hootsuite

Chiến Thuật Marketing & Sales Cuối Năm Và Vai Trò Của GTG CRM Trong Việc Bứt Tốc Doanh Thu

Sức mạnh của Content Marketing: Bài học từ 4 case study huyền thoại
